Cette section décrit nos méthodes de collecte de données les plus couramment utilisées, les types de données que nous avons recueillies, la façon dont nous les avons utilisées et certaines contraintes importantes dont il faut tenir compte, en particulier dans l’interprétation de nos questions de recherche. Elle porte également sur la façon dont nous formulons nos questions de recherche pour commencer nos travaux et sur l’utilisation des résultats de nos recherches.
Il est souvent question d’éliminer le cloisonnement dans le secteur public. Souvent, au gouvernement, la recherche est effectuée par une équipe distincte de celles qui dirigent l’expérimentation, qui sont toutes deux distinctes du cycle de développement de la prestation réelle du produit.
Tout en éliminant le cloisonnement entre ces secteurs si le travail est important, au Nuage de talents, nous avons pris une orientation différente, en regroupant chacune des composantes de notre cycle de développement en un seul endroit (voir la section sur les activités de l’équipe). Cela nous aide à travailler efficacement, nous maintient sur la même voie et favorise la responsabilisation dans l’ensemble de l’équipe de produit.
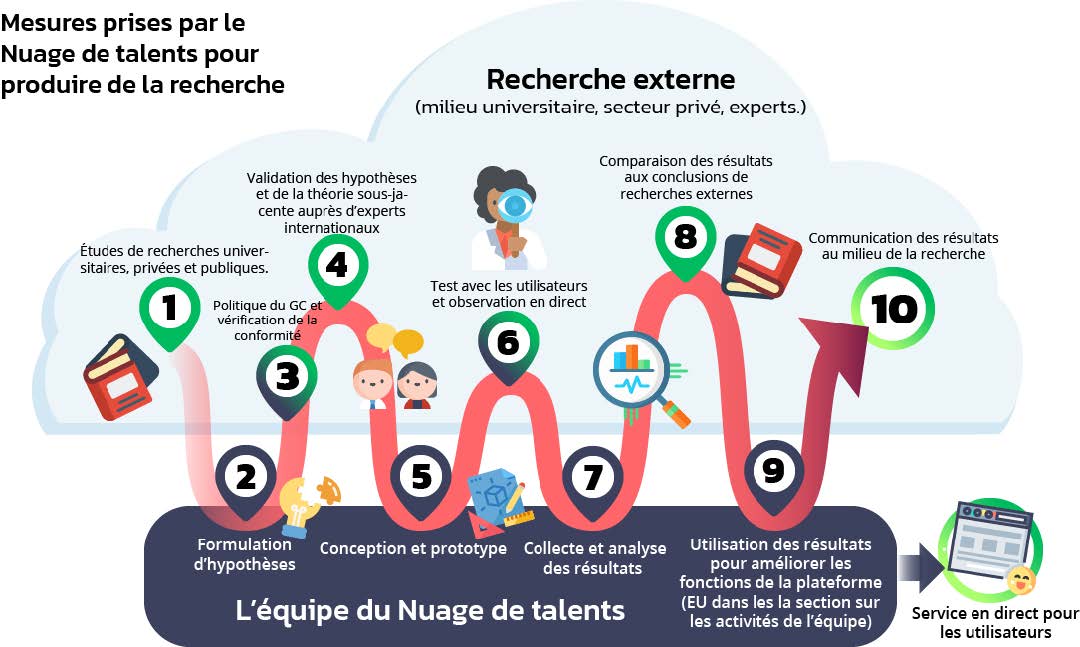
Comment le cycle de recherche s’inscrit-il dans le cycle de développement de l’équipe? Voici comment fonctionne notre cycle de recherche, en commençant par examiner ce qui existe au-delà du gouvernement et en terminant par la transmission des conclusions à la collectivité plus vaste.
Méthodologies de recherche
La plateforme et les fonctions qui composent le Nuage de talents peuvent être divisées en une série d’expériences. Chacune de ces expériences a commencé par des recherches externes. Il existait parfois des pratiques ou des normes largement adoptées que nous pouvions utiliser, mais parfois les réponses n’étaient pas aussi faciles à trouver.
Avec nos premières recherches documentaires en main, nous sommes passés à des projets pilotes avec de vraies personnes et de véritables processus d’emploi pour tester nos hypothèses, tout en effectuant des vérifications de conformité par rapport aux politiques gouvernementales. Bien que nous n’ayons pas une taille d’échantillon nécessaire pour mener des essais contrôlés randomisés, il existe de nombreuses autres méthodes de recherche, quoique moins puissantes, pour ce type de travail. Nous ne nous sommes pas appuyés non plus sur une seule approche, mais nous nous sommes plutôt adaptés afin de trouver le meilleur outil pour le travail que nous devions réaliser. Nos méthodologies s’inspirent de la psychologie comportementale, de la refonte de processus allégée, de la conception centrée sur la personne et des méthodes de recherche qualitative et quantitative traditionnelles.
Une fois les résultats du projet pilote connus, nous les avons comparés à des données externes pour valider nos conclusions. Il est toujours important de comparer les résultats à d’autres ou à des données de référence, mais c’est particulièrement essentiel lorsqu’il s’agit de très petits échantillons, comme c’était le cas pour les emplois affichés sur le site. Cela nous a également aidés à mieux comprendre les processus et les comportements qui façonnent la dotation et le recrutement de talents.
Données qualitatives
Au cours du projet, nous avons recueilli une importante quantité de données qualitatives. Nous avons organisé des ateliers avec chaque groupe d’utilisateurs avant de commencer l’étape de la conception. Une fois que la conception a débuté, nous avons testé des prototypes de maquette conceptuelle, rapidement et souvent, en observant si les personnes utilisaient les fonctions comme nous le pensions, puis en leur demandant ce qu’elles aimaient ou non. Elles nous ont également accompagnés à des présentations, destinées à nos ministères partenaires ou au grand public, et nous leur avons demandé ce qu’elles en pensaient.
Nous avons continué de recueillir des données qualitatives sur les fonctions après leur lancement. Notre coordonnateur de projet a observé la façon dont la plateforme était utilisée et a signalé de nombreux problèmes que nous avons pu régler rapidement, grâce à notre surveillance. L’équipe compilait aussi régulièrement des courriels d’utilisateurs dans lesquels des tendances étaient ciblées et les envoyait à nos concepteurs d’expérience utilisateur.
Nous avons également déployé des efforts considérables pour communiquer avec tous ceux qui ont utilisé la plateforme, en vue de connaître leur opinion. Il s’agissait en grande majorité d’entrevues semi-structurées. Assez rapidement, nous avons élaboré un guide d’entrevue pour orienter la conversation sur certaines de nos questions clés, mais nous avons fait preuve d’une grande souplesse pour permettre les digressions et suivre le fil de la pensée de nos participants.
Nous avons également envoyé des sondages aux gestionnaires qui affichaient des emplois sur le site et aux candidats à ces emplois. Bien que plusieurs questions du formulaire étaient de nature quantitative, nous avons obtenu certains des renseignements les plus riches des boîtes de texte ouvertes.
Données quantitatives
Les autorités des RH du GC recueillent une quantité importante de données sur le processus d’embauche, ce qui contribue aux connaissances du GC en matière de tendances et de priorités. Cela étant, lorsque nous avons examiné nos deux principaux objectifs de recherche (le temps nécessaire pour doter le poste et l’adéquation en matière de diversité/culture), bon nombre de nos questions portait sur des problèmes au sujet desquels les données n’étaient pas recueillies ou pour lesquels nous n’étions pas en mesure d’accéder facilement aux constatations (p. ex., au moyen du Portail du gouvernement ouvert).
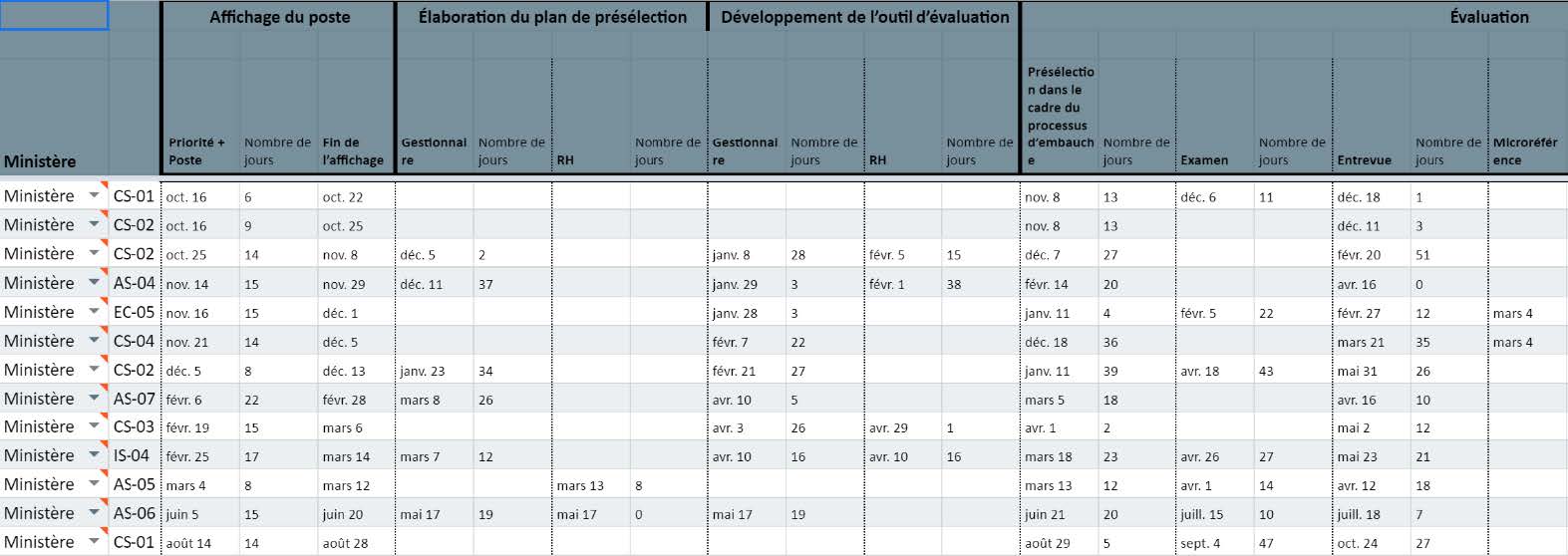
Les données sur les processus de dotation réels exécutés dans le Nuage de talents constituaient une source de données importante que nous avons utilisée pour mettre à l’essai nos questions de recherche. Pour ce faire, nous avons recueilli des données sur la dotation qui n’étaient pas facilement accessibles à ce niveau de détail ailleurs au GC. Nous avons consigné la durée de chaque étape du processus d’embauche, ainsi que du nombre de candidats qui ont réussi chaque phase du processus d’évaluation. Par exemple, nous avons examiné minutieusement des éléments comme le nombre de fois qu’une ébauche d’offre d’emploi va et vient entre les conseillers en RH et les gestionnaires, le nombre de candidats qui ont présenté une candidature le dernier jour d’une offre d’emploi, et la façon dont les étapes du processus, comme la traduction et la saisie des données, influent sur l’ordre et le calendrier des approbations.
Détails à l’entrée, détails à la sortie
Toutes ces données ont été saisies manuellement dans une base de données distincte par l’administrateur système. (Nous avions prévu qu’une fois que la plateforme couvrirait le processus de dotation du début à la fin, ce processus serait automatisé au moyen de fichiers journaux.) Le fait d’avoir accès à cette information détaillée nous a aidés à déterminer les moments les processus s’enlisent et les points qui nécessitent des améliorations aux processus ou plutôt des interventions comportementales.
Faible puissance
En raison des contraintes liées à la taille de l’échantillon (53 emplois ont été affichés depuis la mise en service de la plateforme, dans de nombreux ministères, classifications et niveaux), il n’est pas encore possible d’effectuer une analyse statistique des données. Par conséquent, lorsque nous parlons de nos résultats sur les processus de travail, il ne faut pas oublier que leur puissance est faible. Nous essayons d’atténuer ce point en examinant de multiples sources de données et en comparant nos données lorsque cela est possible.
Cependant, du côté des candidats, nous avons dépassé le seuil de 1 000, ce qui commence à constituer le volume dont nous avons besoin pour obtenir des résultats statistiquement significatifs. Sur ce point également, notre capacité de mettre à l’essai certaines de nos questions de recherche a été limitée par les renseignements que nous pouvons recueillir. Sans serveur « Protégé B », certaines actions nous sont impossibles, comme recueillir des données sur l’équité en matière d’emploi sur le site ou pousser notre recherche sur la diversité dans le domaine des données qualitatives.
Nous ne souhaitons pas surestimer la fiabilité de nos conclusions. Nous avons réalisé une expérience à petite échelle et nous n’avons pas un échantillon de taille statistiquement suffisante pour mener des essais contrôlés randomisés. Bien que nous comparions les résultats des recherches externes avec nos conclusions quantitatives et qualitatives, nos résultats de recherche devraient être considérés comme ayant une faible puissance, et non comme des solutions définitives.
La valeur des intuitions
On ne peut pas créer une politique fondée sur des données probantes sans données probantes. C’était l’objectif du Nuage de talents.
Lorsque nous présentons nos résultats, notre public approuve souvent. Qu’il s’agisse de gestionnaires ou de conseillers en RH, nous constatons que nous confirmons beaucoup de choses qu’ils savent depuis des années, mais pour lesquelles ils n’ont pas nécessairement de chiffres ou d’histoires à l’appui. Voici un commentaire que nous entendons souvent : « Nous le savions déjà. Quelle est donc la prochaine étape? »
Étant donné que le hochement de tête d’une foule ne constitue pas un point de données quantitatif valide pour confirmer les résultats, nous effectuons un suivi au moyen d’entrevues, de groupes de discussion et de tests en direct de nouvelles fonctions, ce qui nous aide à valider les intuitions difficiles à valider – reconnues depuis longtemps, mais non statistiquement prouvées – en jeu dans l’espace de dotation du GC.
Après tout, les « intuitions » ne sont souvent que la reconnaissance d’une tendance pluriannuelle par des experts sur le terrain, comme les conseillers en RH et les gestionnaires chevronnés. Et nous prenons le temps d’écouter ces intuitions et d’explorer la psychologie comportementale et la conception des systèmes sous-jacents au problème, ce qui, nous l’espérons, mène à des solutions potentielles.
L’effet paralysant de la COVID-19 sur la recherche
Comme pour le reste du monde, la COVID-19 a eu une incidence importante sur les activités du Nuage de talents. Lorsque les employés ont été renvoyés chez eux pour une période indéterminée à la mi-mars, la dotation en personnel s’est pratiquement arrêtée. Dix offres d’emploi ont été affichées d’avril à juin 2019, mais aucun emploi n’a été affiché pendant la même période en 2020. Nous avons également observé que les processus d’évaluation des emplois ont considérablement ralenti, et une plus grande proportion d’emplois ont été annulés en raison de contraintes financières par le ministère. (Remarque : Les quelques nouveaux emplois qui ont été lancés au cours de l’été 2020 ont été en mesure de profiter des mises à niveau de la plateforme et, par conséquent, nous avons vu le temps de dotation diminuer considérablement avec ces processus.)
L’année 2020 était l’année où nous avions prévu d’augmenter considérablement l’envergure de notre projet et d’obtenir les tailles d’échantillon dont nous avions besoin pour que nos résultats soient appuyés par une certaine puissance statistique. Au lieu de cela, nous avons rapidement pivoté pour essayer de faciliter la mobilité des talents internes à l’échelle du GC, le gouvernement s’étant organisé pour appuyer les personnes, les entreprises et les besoins internes changeants (pour en savoir plus sur la réserve de talents du GC, voir la section 5 du présent rapport).